
Haystack 概念概述
Haystack 提供了构建自定义代理和 RAG 管道所需的所有工具,并能通过 LLM 为您提供服务。这包括从原型设计到部署的所有环节。本页将讨论 Haystack 操作的最重要概念。
组件
Haystack 提供了各种组件,每个组件都执行不同类型的任务。您可以在左侧导航栏的“管道组件”部分看到所有组件。这些组件通常由最新的大型语言模型 (LLM) 和 Transformer 模型驱动。在代码层面,它们是可直接调用方法的 Python 类。最常见的情况是,您只需使用所需的参数初始化组件,然后使用run() 方法运行它。
在 Haystack 组件的这一层级工作是一种动手实践的方法。组件定义了所有输入和输出的名称和类型。组件 API 降低了复杂性,并使创建自定义组件(例如,用于第三方 API 和数据库)变得更加容易。Haystack 会在运行管道之前验证组件之间的连接,并在需要时生成带有修复错误说明的错误消息。
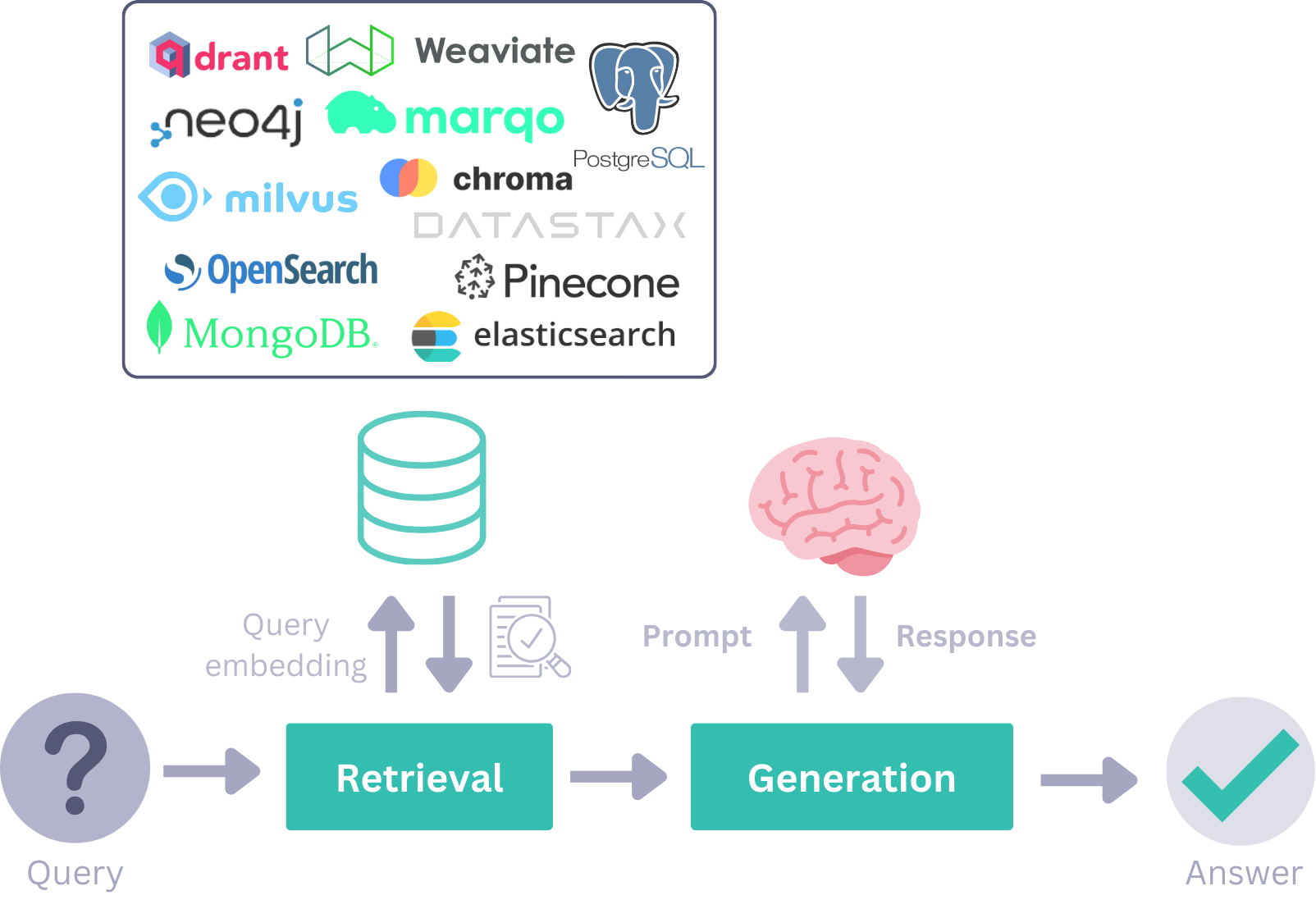
Generators (生成器)
生成器在您提供提示后负责生成文本响应。它们针对每种 LLM 技术(OpenAI、Cohere、本地模型等)都有特定的生成器。生成器有两种类型:聊天和非聊天。
- 聊天生成器支持聊天完成,专为对话场景而设计。它期望接收一个消息列表来与用户进行交互。
- 非聊天生成器使用 LLM 进行更简单的文本生成(例如,翻译或总结文本)。
在我们的指南中阅读有关各种生成器的更多信息。
Retrievers (检索器)
检索器会遍历 Document Store 中的所有文档,选择与用户查询匹配的文档,然后将其传递给下一个组件。有各种检索器是针对特定 Document Store 定制的。这意味着它们可以使用定制的参数来处理每个数据库的特定需求。
例如,对于 Elasticsearch Document Store,您会在其 GitHub 仓库中找到 Document Store 和 Retriever 的软件包。
Document Stores (文档存储)
Document Store 是一个在 Haystack 中存储文档的对象,就像存储数据库的接口一样。它使用特定函数,例如write_documents() 或delete_documents() 来处理数据。各种组件都可以访问 Document Store,并可以通过读取或写入文档等方式与其交互。
如果您正在使用 Haystack 中更复杂的管道,可以使用 DocumentWriter 组件为您将数据写入 Document Store。
Data Classes (数据类)
您可以在 Haystack 中使用不同的数据类在系统中传递数据。数据类最有可能作为管道的输入或输出出现。
Document 类包含要在管道中传递的信息。它可以是文本、元数据、表格或二进制数据。文档可以写入 Document Store,也可以被其他组件写入和读取。
Answer 类不仅包含管道中生成的答案,还包含原始查询和元数据。
Pipelines (管道)
最后,您可以将各种组件、Document Store 和集成组合成管道,以创建强大且可定制的系统。这是一个高度灵活的系统,允许您拥有并发流、独立组件、循环和其他类型的连接。您可以在一个管道中完成预处理、索引和查询步骤,也可以根据您的需求将它们拆分。
如果您想重用管道,可以将它们保存到磁盘上的方便格式(YAML、TOML 等),或通过序列化过程在不同地方共享它们。
这是一个简短的 Haystack 管道示例,配有图示:
更新于 5 个月前