
假设文档嵌入 (HyDE)
通过为初始查询生成模拟的假设文档,在 Haystack 中使用 HyDE 方法增强检索。
何时有用?
HyDE 方法在以下情况下非常有用:
- 您的管道中的检索步骤性能不够好(例如,召回率指标较低)。
- 您的检索步骤以查询作为输入,并从更大的文档库中返回文档。
- 如果您的数据(文档或查询)来自一个与检索器训练的典型数据集非常不同的特殊领域,尤其值得一试。
它是如何工作的?
许多嵌入检索器在新颖的、未见过领域的泛化能力较差。这种方法试图解决这个问题。给定一个查询,假设文档嵌入 (HyDE) 首先通过零样本提示一个指令跟随语言模型,生成一个“虚假”的假设文档,该文档捕获了初始查询的相关文本模式——实际上,这会执行五次。然后,它将每个假设文档编码成一个嵌入向量并对它们进行平均。由此产生的单个嵌入可以用来识别文档嵌入空间中的一个邻域,从中根据向量相似性检索到类似的实际文档。与任何其他检索器一样,这些检索到的文档随后可以在管道下游使用(例如,在 RAG 的生成器中)。有关更多详细信息,请参阅论文“Precise Zero-Shot Dense Retrieval without Relevance Labels”。
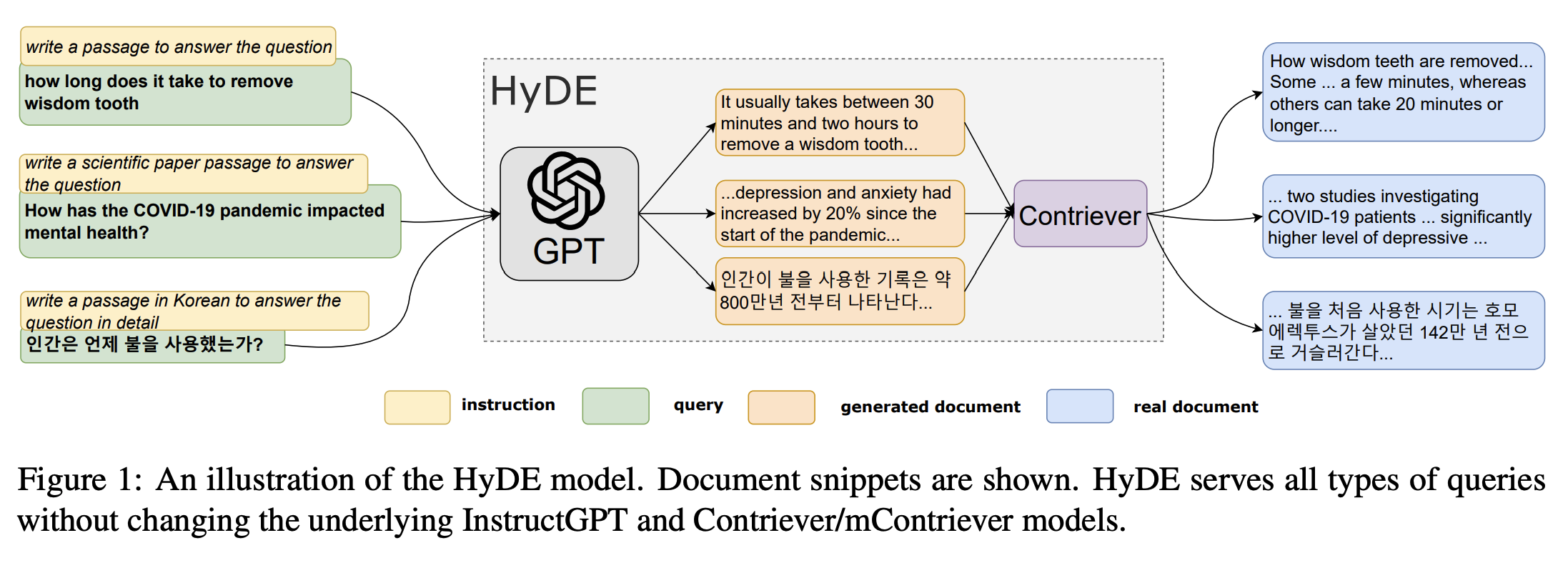
来源:原始论文,Gao 等人,https://aclanthology.org/2023.acl-long.99/
如何在 Haystack 中构建它?
首先,准备您需要的所有组件
import os
from numpy import array, mean
from typing import List
from haystack.components.generators.openai import OpenAIGenerator
from haystack.components.builders import PromptBuilder
from haystack import component, Document
from haystack.components.converters import OutputAdapter
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
# We need to ensure we have the OpenAI API key in our environment variables
os.environ['OPENAI_API_KEY'] = 'YOUR_OPENAI_KEY'
# Initializing standard Haystack components
generator = OpenAIGenerator(
model="gpt-3.5-turbo",
generation_kwargs={"n": 5, "temperature": 0.75, "max_tokens": 400},
)
prompt_builder = PromptBuilder(
template="""Given a question, generate a paragraph of text that answers the question. Question: {{question}} Paragraph:""")
adapter = OutputAdapter(
template="{{answers | build_doc}}",
output_type=List[Document],
custom_filters={"build_doc": lambda data: [Document(content=d) for d in data]}
)
embedder = SentenceTransformersDocumentEmbedder(model="sentence-transformers/all-MiniLM-L6-v2")
embedder.warm_up()
# Adding one custom component that returns one, "average" embedding from multiple (hypothetical) document embeddings
@component
class HypotheticalDocumentEmbedder:
@component.output_types(hypothetical_embedding=List[float])
def run(self, documents: List[Document]):
stacked_embeddings = array([doc.embedding for doc in documents])
avg_embeddings = mean(stacked_embeddings, axis=0)
hyde_vector = avg_embeddings.reshape((1, len(avg_embeddings)))
return {"hypothetical_embedding": hyde_vector[0].tolist()}
然后,将它们全部组装成一个管道
from haystack import Pipeline
pipeline = Pipeline()
pipeline.add_component(name="prompt_builder", instance=prompt_builder)
pipeline.add_component(name="generator", instance=generator)
pipeline.add_component(name="adapter", instance=adapter)
pipeline.add_component(name="embedder", instance=embedder)
pipeline.add_component(name="hyde", instance=HypotheticalDocumentEmbedder())
pipeline.connect("prompt_builder", "generator")
pipeline.connect("generator.replies", "adapter.answers")
pipeline.connect("adapter.output", "embedder.documents")
pipeline.connect("embedder.documents", "hyde.documents")
query = "What should I do if I have a fever?"
result = pipeline.run(data={"prompt_builder": {"question": query}})
# 'hypothetical_embedding': [0.0990725576877594, -0.017647066991776227, 0.05918873250484467, ...]}
这是结果管道的图
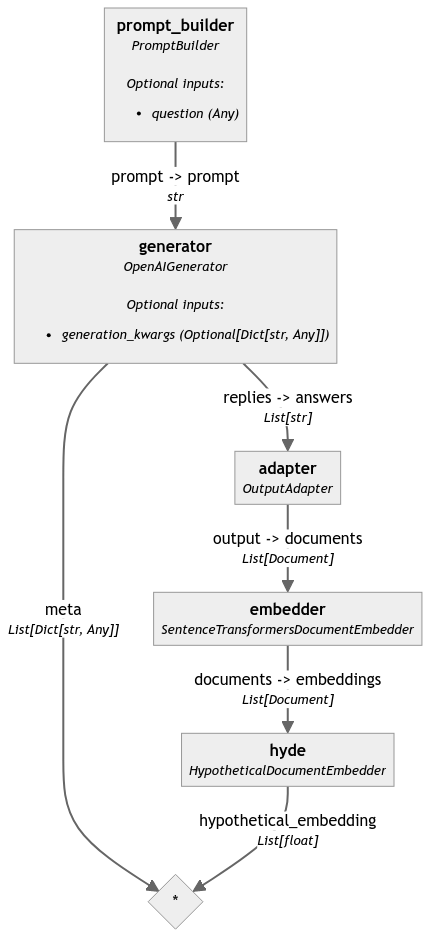
这个管道示例将您的查询转换为一个嵌入。
您可以继续将此嵌入馈送到任何基于嵌入的检索器,以在您的文档存储中查找相似的文档。
其他参考资料
📚 文章:使用 HyDE 优化检索
🧑🍳 食谱:使用假设文档嵌入 (HyDE) 来改进检索
更新于 大约 1 年前