
Pipelines (管道)
要使用 LLM 构建现代搜索管道,您需要两样东西:强大的组件和一种将它们组合在一起的简便方法。Haystack 管道就是为此目的而构建的,它使您能够设计和扩展与 LLM 的交互。
Haystack 中的管道是不同 Haystack 组件和集成的有向多图。它们赋予您以各种方式连接这些组件的自由。这意味着管道不必是连续的信息流。借助 Haystack 管道的灵活性,您可以实现同时流、独立组件、循环和其他类型的连接。
灵活性
Haystack 管道的功能远不止查询和索引管道。管道的功能,无论是索引、查询、从 API 获取、预处理还是其他功能,完全取决于您如何设计管道以及使用哪些组件。虽然您仍然可以创建单功能管道,例如使用现成组件来清理、拆分并将文档写入 Document Store 的索引管道,或者仅接受查询并返回答案的查询管道,但 Haystack 允许您使用决策组件(例如ConditionalRouter)将多个用例合并到一个管道中。
代理管道
Haystack 中的循环和分支支持创建复杂的应用程序,例如代理。以下是如何创建它们的几种示例:
- 教程:使用函数调用构建聊天代理
- 教程:构建带有回退到网络搜索的代理式 RAG
- 教程:通过基于循环的自动更正生成结构化输出
- 食谱:定义和运行工具
- 食谱:使用内存进行对话式 RAG
- 食谱:带有实验性 Haystack 工具的邮件发送代理
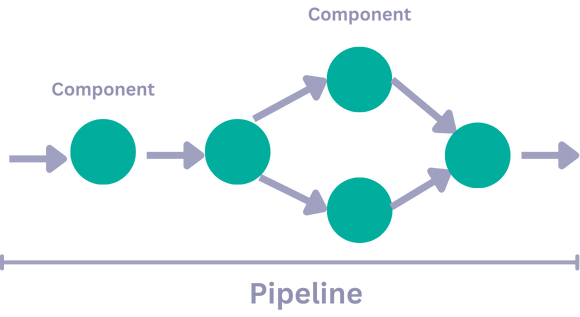
分支
一个管道可以有多个分支同时处理数据。例如,要处理不同的文件类型,您可以有一个包含多个转换器的管道,每个转换器处理一种特定的文件类型。然后,您将所有文件输入管道,管道会智能地将它们同时进行划分并路由到适当的转换器,从而省去了您逐个发送文件进行处理的麻烦。
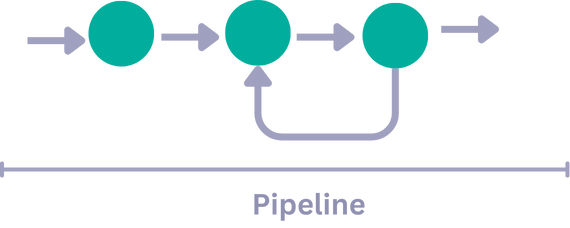
循环
管道中的组件可以执行迭代循环,您可以在所需数量处进行限制。这对于自纠正循环等场景非常有用,您可以在其中有一个生成器生成输出,然后由验证器组件检查输出是否正确。如果生成器的输出存在错误,验证器组件可以循环回生成器以获取更正后的输出。循环将一直进行,直到输出通过验证并可以发送到管道的下游。
异步管道
当依赖关系允许时,AsyncPipeline 支持 Haystack 组件的并行执行。这提高了具有独立操作的复杂管道的性能。例如,它可以同时运行多个检索器或 LLM 调用,并行执行独立的管道分支,并有效处理可能导致延迟的 I/O 密集型操作。通过并发执行,AsyncPipeline 显著减少了与顺序执行相比的总处理时间。
在我们的 AsyncPipeline 文档中了解更多信息。
SuperComponents
为了简化您的代码,我们引入了 SuperComponents,它允许您包装完整的管道并将它们作为单个组件重用。有关详细信息和示例,请查看它们的文档页面。
数据流
虽然数据(初始查询)会流经整个管道,但单个值仅在连接时才从一个组件传递到另一个组件。因此,并非所有组件都能访问所有数据。这种方法带来了速度和易于调试的好处。
要将管道中的组件和集成连接起来,您必须知道它们的输入和输出名称。一个组件的输出必须被下一个组件接受作为输入。当您使用Pipeline.connect() 连接管道中的组件时,它会验证输入和输出类型是否匹配。
创建管道的步骤说明
创建完所有组件并准备好将它们组合到管道中后,有四个步骤可以使其正常工作:
- 使用
Pipeline().
创建管道。这会创建 Pipeline 对象。 - 使用
.add_component(name, component).
将组件逐个添加到管道中。这只是将组件添加到管道而尚未连接它们。这对于循环特别有用,因为它允许在下一步中顺畅地连接组件,因为它们都已存在于管道中。 - 使用
.connect("producer_component.output_name", "consumer_component.input_name").
连接组件。在这一步,您明确地将组件的一个输出连接到下一个组件的一个输入。此时,管道会在不运行组件的情况下验证连接。这使得验证过程速度很快。 - 使用
.run({"component_1": {"mandatory_inputs": value}}).
运行管道。最后,您可以通过指定管道中的第一个组件并传递其强制输入来运行管道。您可以选择性地将输入传递给其他组件,例如:.run({"component_1": {"mandatory_inputs": value}, "component_2": {"inputs": value}}).
《创建管道》中的完整管道 示例 展示了所有元素如何组合在一起创建一个工作的 RAG 管道。
创建管道后,您可以 在图形中可视化它,以了解组件的连接方式并确保其符合您的期望。您可以使用 Mermaid 图来实现这一点。
验证
当您使用.connect() 连接管道组件时,验证就会发生,但会在运行组件之前进行,以加快速度。管道会验证:
- 组件存在于管道中。
- 组件的输出和输入匹配并且已明确指示。例如,如果一个组件生成两个输出,在将其连接到另一个组件时,您必须指明哪个输出连接到哪个输入。
- 组件的类型匹配。
- 对于除
Variadic之外的输入类型,检查输入是否已被另一个连接占用。
所有这些检查都会产生详细的错误,以帮助您快速修复已识别的任何问题。
序列化
得益于序列化,您可以保存然后加载您的管道。序列化是将 Haystack 管道转换为您可以存储在磁盘或通过网络发送的格式。它对于以下方面特别有用:
- 编辑、存储和共享管道。
- 以不同于 Python 的格式修改现有管道。
Haystack 管道将序列化委托给其组件,因此序列化管道只需按顺序序列化管道中的每个组件以及它们的连接。管道被序列化为字典格式,该格式充当您可以将其转换为所需最终格式的中间格式。
序列化格式
目前 Haystack 只支持 YAML 格式。我们将逐步推出更多格式。
为了实现序列化,组件必须支持与 Python 字典之间的转换。所有 Haystack 组件都有两个方法使其可序列化:from_dict 和to_dict。而Pipeline 类则有其自己的from_dict 和to_dict 方法,该方法负责序列化组件和连接。
更新于 5 个月前