
创建管道
了解创建管道的一般原则。
您可以使用这些说明来创建索引管道和查询管道。
此任务使用语义文档搜索管道的示例。
先决条件
对于您想在管道中使用的每个组件,您都必须知道其输入和输出的名称。您可以在特定组件的文档页面或组件的run() 方法中找到它们。有关更多信息,请参阅 组件:输入和输出。
创建管道的步骤
1. 导入依赖项
导入所有依赖项,例如 pipeline、documents、Document Store 以及您想在管道中使用的所有组件。
例如,要创建语义文档搜索管道,您需要Document 对象、pipeline、Document Store、Embedders 和 Retriever。
from haystack import Document, Pipeline
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.components.embedders import SentenceTransformersTextEmbedder
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever
2. 初始化组件
初始化组件,传入您想配置的任何参数。
document_store = InMemoryDocumentStore(embedding_similarity_function="cosine")
text_embedder = SentenceTransformersTextEmbedder()
retriever = InMemoryEmbeddingRetriever(document_store=document_store)
3. 创建管道
query_pipeline = Pipeline()
4. 添加组件
逐个将组件添加到管道中。添加的顺序并不重要。
query_pipeline.add_component("component_name", component_type)
# Here is an example of how you'd add the components initialized in step 2 above:
query_pipeline.add_component("text_embedder", text_embedder)
query_pipeline.add_component("retriever", retriever)
# You could also add components without initializing them before:
query_pipeline.add_component("text_embedder", SentenceTransformersTextEmbedder())
query_pipeline.add_component("retriever", InMemoryEmbeddingRetriever(document_store=document_store))
5. 连接组件
通过指示一个组件的哪个输出应连接到下一个组件的输入来连接组件。如果一个组件只有一个输入或输出,并且连接很明显,您可以只传入组件名称而不指定输入或输出。
要了解运行管道所需的输入,请使用.inputs() pipeline 函数。请参阅下文 Pipeline Inputs 部分的详细示例。
以下是代码中更直观的解释。
# This is the syntax to connect components. Here you're connecting output1 of component1 to input1 of component2:
pipeline.connect("component1.output1", "component2.input1")
# If both components have only one output and input, you can just pass their names:
pipeline.connect("component1", "component2")
# If one of the components has only one output but the other has multiple inputs,
# you can pass just the name of the component with a single output, but for the component with
# multiple inputs, you must specify which input you want to connect
# Here, component1 has only one output, but component2 has mulitiple inputs:
pipeline.connect("component1", "component2.input1")
# And here's how it should look like for the semantic document search pipeline we're using as an example:
pipeline.connect("text_embedder.embedding", "retriever.query_embedding")
# Because the InMemoryEmbeddingRetriever only has one input, this is also correct:
pipeline.connect("text_embedder.embedding", "retriever")
您需要将所有组件链接在一起,逐渐将它们成对连接。以下是我们正在组装的管道的显式示例。
# Imagine this pipeline has four components: text_embedder, retriever, prompt_builder and llm.
# Here's how you would connect them into a pipeline:
query_pipeline.connect("text_embedder.embedding", "retriever")
query_pipeline.connect("retriever","prompt_builder.documents")
query_pipeline.connect("prompt_builder", "llm")
6. 运行管道
等待管道验证组件和连接。如果一切正常,您现在就可以运行管道了。Pipeline.run() 可以通过两种方式调用,一种是传入组件名称及其输入的字典,另一种是直接传入仅输入。当直接传入时,pipeline 会将输入解析到正确的组件。
# Here's one way of calling the run() method
results = pipeline.run({"component1": {"input1_value": value1, "input2_value": value2}})
# The inputs can also be passed directly without specifying component names
results = pipeline.run({"input1_value": value1, "input2_value": value2})
# This is how you'd run the semantic document search pipeline we're using as an example:
query = "Here comes the query text"
results = query_pipeline.run({"text_embedder": {"text": query}})
管道输入
如果您需要了解运行管道所需的组件输入,Haystack 提供了一个有用的 pipeline 函数.inputs(),该函数列出了组件所需的所有输入。
这是它的工作原理:
# A short pipeline example that converts webpages into documents
from haystack import Pipeline
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.components.fetchers import LinkContentFetcher
from haystack.components.converters import HTMLToDocument
from haystack.components.writers import DocumentWriter
document_store = InMemoryDocumentStore()
fetcher = LinkContentFetcher()
converter = HTMLToDocument()
writer = DocumentWriter(document_store = document_store)
pipeline = Pipeline()
pipeline.add_component(instance=fetcher, name="fetcher")
pipeline.add_component(instance=converter, name="converter")
pipeline.add_component(instance=writer, name="writer")
pipeline.connect("fetcher.streams", "converter.sources")
pipeline.connect("converter.documents", "writer.documents")
# Requesting a list of required inputs
pipeline.inputs()
# {'fetcher': {'urls': {'type': typing.List[str], 'is_mandatory': True}},
# 'converter': {'meta': {'type': typing.Union[typing.Dict[str, typing.Any], typing.List[typing.Dict[str, typing.Any]], NoneType],
# 'is_mandatory': False,
# 'default_value': None},
# 'extraction_kwargs': {'type': typing.Optional[typing.Dict[str, typing.Any]],
# 'is_mandatory': False,
# 'default_value': None}},
# 'writer': {'policy': {'type': typing.Optional[haystack.document_stores.types.policy.DuplicatePolicy],
# 'is_mandatory': False,
# 'default_value': None}}}
从上面的响应中,您可以看到urls 输入对于LinkContentFetcher 是必需的。这就是您将如何运行此管道:
pipeline.run(data=
{"fetcher":
{"urls": ["https://docs.haystack.com.cn/docs/pipelines"]}
}
)
示例
此食谱将指导您完成创建 RAG 管道的过程,并解释代码。
以下是此管道的 可视化 Mermaid 图:
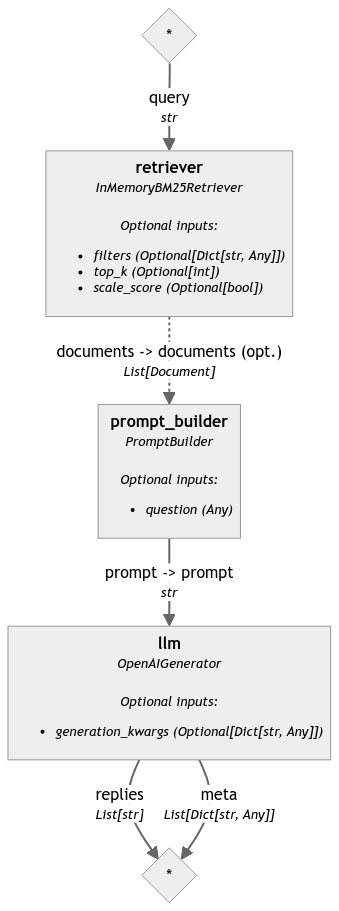
更新于 12个月前